.svg)


In this blog post we’ll show you how we migrated a critical Postgres database with 18Tb of data from Amazon RDS (Relational Database Service) to Amazon Aurora, with minimal downtime. To do so, we’ll discuss our experience at Codacy.
Today, Codacy’s underlying infrastructure relies heavily on Amazon Web Services (AWS), particularly RDS, to host our Postgres databases.
Analysis workflow, behind the scenes
We’ll start with a brief description of the analysis process on Codacy, from the git providers (GitHub, Gitlab or Bitbucket) to the storage of results on the databases.
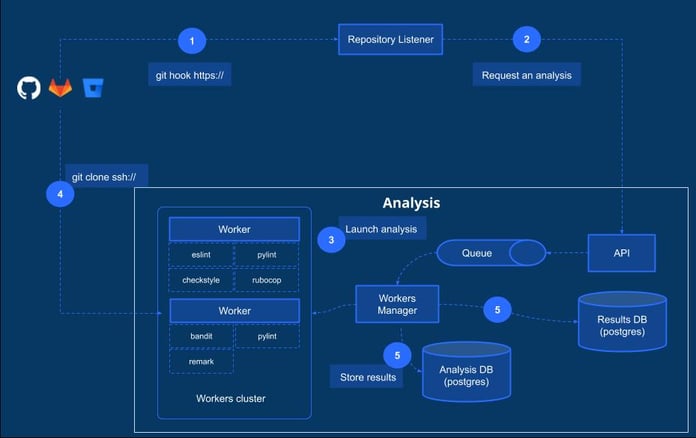
- Whenever a commit or Pull/Merge request is done over a repository, we detect it on our side using hooks.
- “Repository Listener”, our internal component, requests an analysis which is queued.
- Our “Worker Manager” picks up the analysis requests and launches the analysis over the repository.
- The short-living “Workers” perform the analysis. This includes: cloning the repository and executing multiple linters (ESlint, pylint, checkstyle, etc.) over it.
- Final results are then saved in two different databases: 1) The “Results DB”, which stores data related to the issues detected on the repositories; 2) The “Analysis DB”, which stores data related to commits, pull requests, etc.
Data overload
Results DB: In January 2017, Codacy’s “Results DB” had approximately 6Tb of data when the limit on Postgres RDS at the time was 8Tb. Since we were running out of storage space, a new database named “Results DB 2017” was created in July 2017 and new results started to be saved on this new database.*
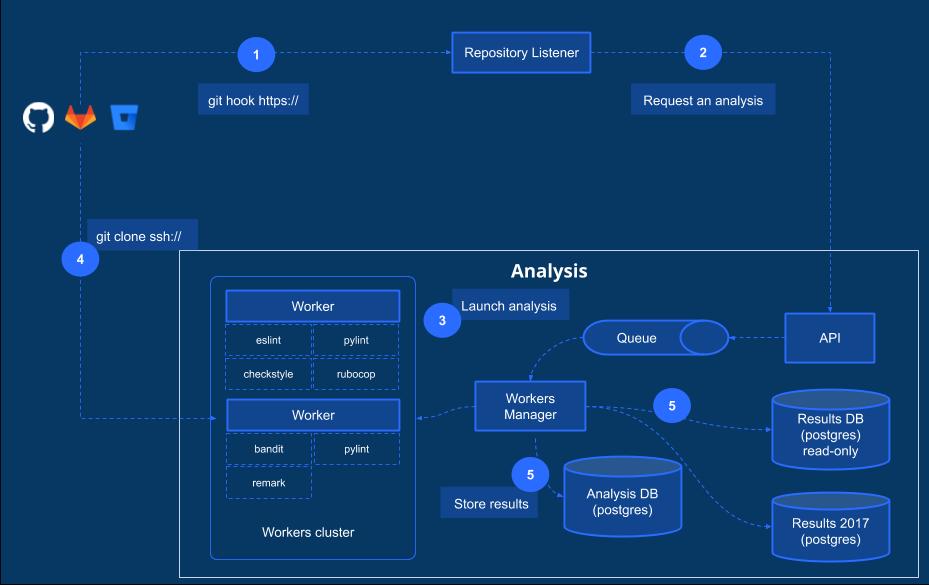
Analysis DB: We experienced a similar issue with “Analysis DB” in Fall 2018. With 14Tb of data, Analysis DB was 2Tb away from the 16Tb data limit. With data growing 500Gb per month we had 4 months to take action. Unlike the previous situation, the schema on this database made it difficult to come up with a simple solution.
Amazon Aurora
We chose Amazon’s Aurora database as a solution for a few key reasons including: 1) automatic storage growth (up to 64Tb); 2) ease of migration from RDS and 3) performance benefits. Although, Aurora’s official docs only claimed up to a 3x increase in throughput performance over stock PostgreSQL 9.6, testimonials claimed that performance increased 12x, just by doing the migration to Aurora.
Migration Process: AWS DMS Vs. alternatives
Once we decided to migrate to Aurora, we had 3 options to do it:
- Use a database snapshot from the original database and migrate it to Aurora. According to AWS support, this option would require 12 hours per Tb.
- Use AWS Database Migration Service (DMS). This option would automatically upgrade our database from Postgres 9.4 to 9.6 (a requirement since 9.6 is the oldest version compatible with Aurora). Although there would be no downtime, the whole process would still be very slow (around 12 hours per Tb). Also, we were concerned that indexes would need to be recreated manually because DMS doesn’t propagate them and it would take a large amount of time to recreate the indexes for our biggest tables.
- Use an Aurora Read Replica. Since it would require the least amount of downtime, we chose to use an AWS replica. We verified that it was taking between 2 and 3 hours per TB during dry runs. Therefore, we could leave Codacy running for that time period on the old database without any impact. Although we needed to manually upgrade the database to 9.6 Tb, the process seemed straightforward
First round: From Postgres 9.4 to 9.6
Upgrading from Postgres 9.4 to 9.6 databases basically consisted in running two commands using the AWS CLI, as described here. Since the whole process could take around 1 hour, we planned to do it on a Saturday morning when we had less people running analysis. We warned our users days before, deployed Codacy’s maintenance page and then started the upgrade.
Oops! After the upgrade, Codacy was running slowly, taking several minutes to load data from the database. Within a few minutes, we decided to revert everything and investigate the problem later.
A second look…
So, we took a better look at the aws official docs and noticed a recommendation to run the ANALYZE operation to refresh the pg_statistic table. This internal table is important for query performance since it stores statistics that are used by the query planner (you can read more about it here).
Before trying the migration task again, we tested the ANALYZE operation on a test database and noticed that it could take several hours to finish. Therefore, we started to research ways to run it faster and we ended up using the vacuumdb utility. Here’s the command that we ran:vacuumdb -Ze -h analysisdb --analyze-in-stages -j 20
These are the important parts:
analyze-in-stages: some statistics are created as fast as possible, to make the database usable and then, the full statistics are produced in the subsequent stages. There are 3 stages in total and after the first one, we verified that the database had already an acceptable performance. And it took only some seconds to finish this first stage!-j 20: it will start 20 jobs to run the analyze command in parallel, reducing the time of the processing.
Second round
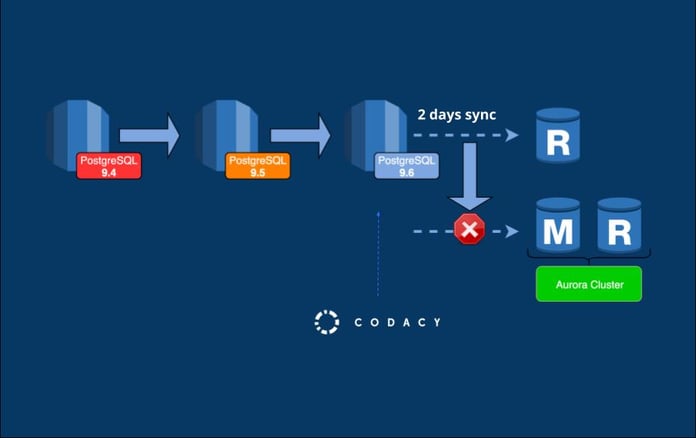
After a successful upgrade, the second, final, migration step was to create an Amazon Aurora PostgreSQL Read Replica using the previous upgraded database. It took around two entire days for the lag between the RDS instance and the Aurora Read Replica to go to 0.
When it happened, we promoted the read replica to master, breaking the link with the source database which stopped the replication. In order to guarantee full replication of the two instances, we stopped every write operation on the source database before doing the promotion. Again, we completed this step on a Saturday morning, since it required downtime.
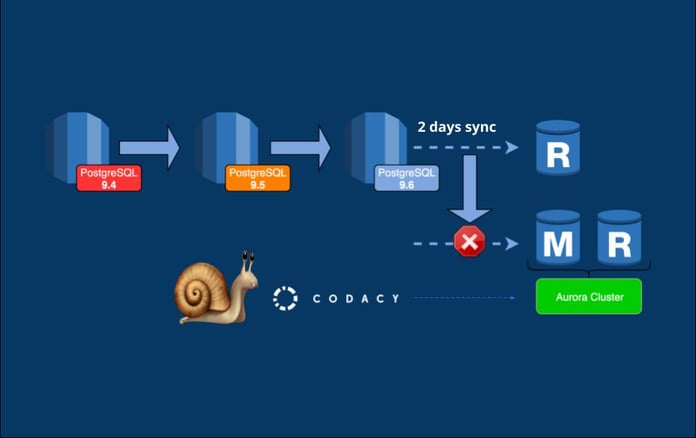
Ironically, again, while we were struggling with the migration and almost running out of time, AWS announced another storage limit increase on RDS for up to 32Tb. However, the AWS support team had to upgrade the underlying filesystem of the database from 32 to 64 bits to be able to use more than 16Tb. We had to stop any transactions on the database for this upgrade to happen on their side and the whole operation took around 2 hours of downtime. Despite this, we were already committed to Aurora migration and decided to go for it. This also gave us a bit more time to prepare it and we ended up doing it only on May 2019, with a bit more than 18Tb on the database.
Wins
Besides having automatic storage provisioning as needed, up to 64Tb, positive outcomes of migration included:
Performance insights
Previously, we were using pgbadger to generate HTML reports from the logs and get useful statistics about query performance on the database. With Aurora we got Performance Insights out of the box and we are now able to get useful, always updated, statistics straight from the AWS Management Console.
Write latency
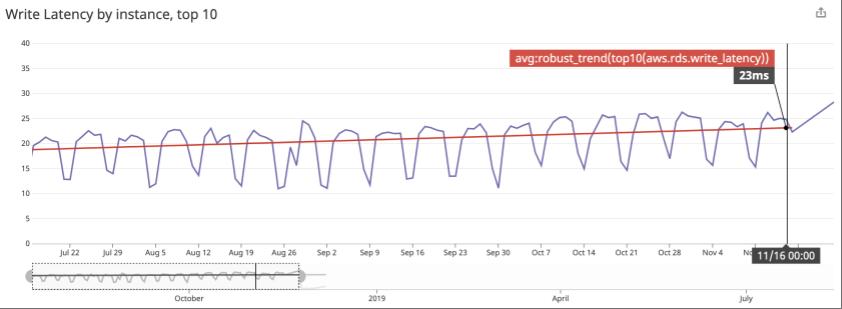
We also had performance improvements to the latency of the write operations.
As it is visible, the latency was slowly increasing on RDS, reaching an average of 23ms on November 2018.
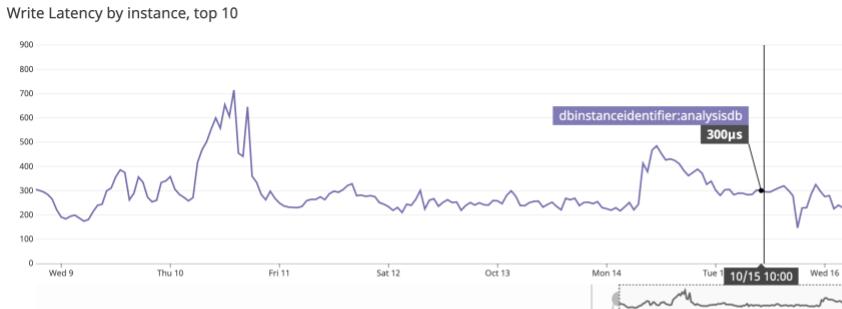
On Aurora, the write latency is now in the order of microseconds. Not bad!
Future
So, what could we do in the future?
Aurora serverless
Databases on AWS can get expensive, especially with the large amounts of data that we have on some databases. Aurora Serverless, however, is able to seamlessly scale compute and memory capacity as needed. Therefore, we can reduce the resources for our database automatically when we have less load on it (for instance, during weekends).
Consider different types of databases, other than Postgres
Postgres is great, but we are using it for almost everything and, in some situations, maybe we shouldn’t. To be able to properly scale horizontally, we should start considering other types of databases, like NoSQL databases such as MongoDB, DocumentDB or CouchDB.
* ironically AWS announced support for up to 16Tb of data on RDS, but that was already too late.
– This blog was written by Bruno Ferreira with Paulo Martins
