.svg)

Time to recover is one of the most interesting metrics you should use to evaluate your team’s speed, quality, and overall efficiency of your Engineering performance. This metric is also known as Mean time to recover, Mean time to restore, or MTTR.
There are four key DORA metrics that we will cover in detail:
- Lead time for changes;
- Deployment frequency;
- Time to recover;
- Change failure rate.
In this article, we are focusing on Time to recover. So keep on reading to know what Time to recover is, how we measure it in Pulse, and how your team can start using it to achieve elite engineering performance.
What is Time to recover?
In a nutshell, Time to recover measures how long it takes to recover from failure. This metric is correlated with both the speed and the quality of your engineering team.
“Traditionally, reliability is measured as time between failures. However, in modern software products and services, which are rapidly changing complex systems, failure is inevitable, so the key question becomes: How quickly can service be restored?"
Accelerate: The science of lean software and DevOps: Building and scaling high performing technology organizations
What does Time to recover measure?
Time to recover is a good indicator of teams’ response time and overall development process efficiency. It is one of the most interesting quality metrics for an organization to work on to ensure the availability and correct functioning of their software.
This metric analyzes how quickly your team can identify incidents and their root causes (e.g., a damaged database or a deployment that breaks an existing feature), notify the appropriate people to deal with those incidents, and resolve them fast.
How to read Time to recover?
On the one hand, a Time to recover that is too high indicates that there may be broader issues, like inefficient processes, lack of people, or inadequate team structure. On the other hand, a low Time to recover shows that your team can quickly respond to and resolve incidents.
Your teams’ goal should be to continuously reduce your Time to recover because it means that, when there is an incident, your team can fix it in a timely fashion, and you are not compromising the availability of your software.
Time to recover in Pulse
Products like Pulse make it very easy for your team to know how your Time to recover looks like. Pulse connects seamlessly with GitHub, PagerDuty, or your incident management tool to give you Time to recover and other Engineering metrics out-of-the-box. Your team only needs to focus on making informed decisions to improve your results.
How is Pulse measuring Time to recover?
Pulse measures Time to recover by calculating how long it takes your organization to recover from a failure in production (e.g., service impairment or unplanned outage). It’s computed with the following formula:
average(incident resolved timestamp - incident created timestamp)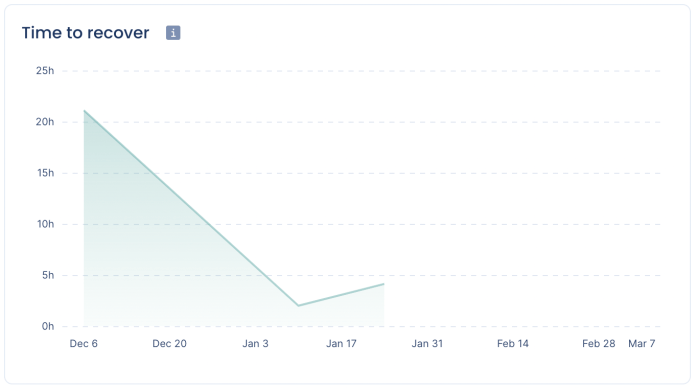
Pulse takes care of all the details to ensure your metrics are accurate and reliable. For example, Pulse automatically associates incidents with the causing deployments, enabling you to explore the metrics by service and each of your GitHub’s team.
What Time to recover should a team have?
The best practice performance level for this metric, published every year on the Accelerate State of DevOps 2021 report:
- Elite: Less than 1 hour
- High: Less than 1 day
- Medium: Less than 1 week
- Low: More than or equal to 1 week
How to use Time to recover
Over time, Time to recover should be getting smaller, while your team increases in the performance level until reaching best practice levels.
Having a small Time to recover allows your team to have a sound overall recovery process, deliver high-quality software quickly, and improve the availability of your software.
Causes of high Time to recover
- Tests being carried out manually;
- Shortage of people or a change in the organizational structure;
- Inefficiencies in the incident management process (e.g., blocks, dependencies, not using the right tools).
How to reduce Time to recover
- Improve your organizational structure: the right people can quickly identify the problem’s root cause and resolve it promptly.
- Use test automation: incorporating automated tests at every stage of the CI/CD pipeline can help you reduce delivery times and help you recover quicker.
- Clearly document the incident management process: continuously train team members on the process and on how to react in case of incidents.
- Find potential steps of the incident management process to be automated: any step your team needs to perform manually – assigning a responsible, or creating a document – adds to Time to recover.
Conclusion
Time to recover is a fundamental metric to analyze and improve the efficiency of your Engineering team. It is a valuable metric to understand the capabilities of your team and how quickly they respond to problems and outages.
Together with Lead time for changes, Deployment frequency, and Change failure rate, this metric provides valuable insights for your team to achieve full engineering performance.
With Pulse, you can easily measure and analyze the Time to recover in your projects and make better decisions.
