.svg)

.jpg?width=1740&height=876&name=Codacy%20Blog%20Thumbnail%20Templates%20(8).jpg)
If you own an Internet-based enterprise, your main branch powers your business and should be protected at all costs. Code reviews are how engineering teams keep an eye on the main branch and ensure high software quality, but how efficient are the current ways of running code reviews?
While many organizations still use pull requests (PR) for code reviews, the PR flow encourages blocking practices like reviewing bigger chunks of code, longer feedback loops, mandatory approvals before merging, and too much focus on implementation details.
If you’re looking for an efficient alternative to implementing continuous code reviews on the main branch without blocking the delivery flow, then this article is for you.
Pull Requests And Their Issues
There are different ways teams can run code reviews. One is the “pull request code review,” a collaborative process where a developer submits a proposal to merge code changes from one branch into another within a version control system. Once the code is reviewed, approved, and meets all quality standards, it is merged into the target branch.
While the PR method enables everyone to work at their own pace and convenience, it promotes some blocking practices during code reviews. Here are some of the issues associated with pull requests:
- Blocking issues: Pull requests act as a gatekeeping mechanism. New functionalities or bug fixes will only be shipped to production if they have been reviewed and approved. Sometimes, merging is blocked by remarks that shouldn’t be blocking (such as cosmetic suggestions and opinions), which can cause unnecessary delays in shipping new features.
- Longer feedback loops: PRs make this feedback loop longer. A developer codes up a feature, but it’s nowhere close to being integrated and working. They now have to wait for the reviewer, go through his remarks, discuss them, change the code, etc.
- Communication issues: Effective communication is crucial for resolving pull requests. Aside from technical skills, every reviewer should be able to communicate clearly and constructively, have patience, and be willing to mentor others. In reality, many developers might not possess these skills.
- Context switching: Teams usually divide the available work into smaller units to work on these pieces independently. As a result, reviewers often need to switch contexts between various tasks, which might be detrimental to the developer’s focus and productivity.
Pull requests make it easier to accept contributions from the outside world, even from those we’re not familiar with. However, as you’ve seen, the process is prone to delays, bottlenecks, and inefficiencies. So what are the non-blocking review alternatives? Let’s take a look.
Pair Reviewing And Its Issues
One common way that teams implement real-time, synchronous code reviews is through pair reviewing (or pair programming). Essentially, code is being reviewed (often by multiple pairs of eyes) as it is written before being committed to the main branch. This approach has minimal impact on the delivery of new features.
Pair reviewing has a lot of merits. For one, pairing allows team members to learn from one another. Overall, it leads to fewer bugs, improvement in code readability, shorter feedback cycles, and knowledge dispersion throughout the team.
It has some disadvantages too. Pairing requires synchronicity and time coordination, which might make it a non-option for remote teams (or even co-located teams with flexible hours). The process can also be quite exhausting.
While pair programming has a lot of benefits, and is more efficient than blocking reviews like pull requests, it’s not the most efficient method of achieving continuous, non-blocking code reviews.
The Concept Of Non-Blocking Code Reviews
Non-blocking code reviews are a modern approach to continuous code review processes that aim to enhance the efficiency and effectiveness of reviewing code changes while minimizing disruptions to the development workflow.
The whole idea is to have a non-blocking flow to code reviews. To break it down, here are its characteristics:
- Incremental changes: Features are split into small shippable pieces that don’t break production and help to speed up the review process. Everything coming through the pipeline is reviewed, but the review isn’t what determines if the code is releasable (if the code passes the test, it works, hence it can be merged). Any issue raised during code review must be addressed promptly to remove poor quality from production.
- Automated checks and exploratory tests: For this to work, teams need to set up automated checks on pull requests, such as unit tests with coverage goals, static analysis for quality and security issues, and linters for code style compliance — all of which Codacy can provide. This stage is critical to the success of nonblocking code review as a process.
- Non-blocking flow: Approvals are not mandatory, meaning developers can ship new code immediately and have it reviewed post-factum. This encourages working in small increments and doing lots of refactorings post-merge. Of course, automated checks should be in place to provide an extra layer of protection around the main branch.
The point is, as long as a service works, it’s not a big deal if its implementation is not as clean or optimal as one could imagine. These aspects can always be improved with continuous refactorings, which can happen while the code is in production.
This non-blocking flow removes the distractions and bottlenecks from the review process, allowing teams to invest time and energy in the activities that improve the overall quality of the code. It streamlines the development process, maintains high code quality, and enhances team productivity by making code reviews a more fluid and integrated part of the development lifecycle.
Benefits of a Non-Blocking Code Review Flow
So why should teams adopt a non-blocking code review approach in their development flow? Here are some benefits of using this method:
- Transaction cost is nearly zero: Because there’s no gating, there are no code delivery delays. The review process doesn’t block new features from being committed to the main branch. This approach also incentivizes teams to work in smaller increments, reducing the cost of code reviews.
- Early and fast feedback: Since the pipeline is never blocked, there is a steady flow of new features/fixes. This gives teams the freedom to make more decisions, run experiments, get more feedback, and find innovative ways to delight their customers (a huge competitive advantage, by the way)
- No context switching: The standard practice in non-blocking code reviews is to review all existing updates before starting new work. This allows team members to work on all features from start to finish. That way, there’s no loss of focus, multitasking, or decrease in productivity.
- No pressure to increase quality: When a new feature goes into production, we know it works, because the tests say so. Even if the code isn’t as clean or optimal as desired, there’s no pressure to increase code quality. There’s all the time to redo the design or rewrite the code. What matters is that the feature passed all tests and is being enjoyed by users.
- There is high trust: Because unreviewed code could also land in production, it puts a high trust in the team. There is a general expectation of the team to do the right thing. Even if something were to go wrong, there is often a continuous integration process in place to resolve these issues quickly.
Now you know how efficient the non-blocking review process is, the next question is how to implement it in your workflow. You’ll need automated tooling to de-risk pushing code to production without human review. Let’s explore how to implement this review method with Codacy.
Continuous, Non-Blocking Code Reviews With Codacy
Codacy’s automated compliance and quality tools allow for the implementation of non-blocking code reviews. For instance, teams can configure it to automatically scan pull requests and block code changes that fall below their organization’s quality standards. Let’s show this in practice. We have a starter Node.js app on GitHub that allows users to register, log in, and view their profile. The plan is to submit a pull request from a separate branch with code that performs the same task but has insecure coding practices and vulnerabilities:
// server.js
const express = require('express');
const bodyParser = require('body-parser');
const session = require('express-session');
const app = express();
// Simulated user database
let users = {};
app.use(bodyParser.urlencoded({ extended: false }));
app.use(session({
secret: 'supersecretkey',
resave: false,
saveUninitialized: true
}));
// Serve static files (for simplicity)
app.use(express.static('public'));
// Register route
app.post('/register', (req, res) => {
const { username, password } = req.body;
// Poor practice: Storing plain text passwords
users[username] = password;
res.send('Registration successful!');
});
// Login route
app.post('/login', (req, res) => {
const { username, password } = req.body;
if (users[username] && users[username] === password) {
req.session.username = username;
res.redirect('/profile');
} else {
res.send('Invalid username or password!');
}
});
// Profile route
app.get('/profile', (req, res) => {
if (req.session.username) {
res.send(`<h1>Welcome, ${req.session.username}!</h1><a
href="/logout">Logout</a>`);
} else {
res.redirect('/');
}
});
// Logout route
app.get('/logout', (req, res) => {
req.session.destroy(() => {
res.redirect('/');
});
});
// Serve a simple form for registration and login
app.get('/', (req, res) => {
res.send(`
<h1>Simple App</h1>
<form action="/register" method="post">
<h2>Register</h2>
<label for="register-username">Username:</label>
<input type="text" id="register-username" name="username"
required><br>
<label for="register-password">Password:</label>
<input type="password" id="register-password" name="password"
required><br>
<button type="submit">Register</button>
</form>
<form action="/login" method="post">
<h2>Login</h2>
<label for="login-username">Username:</label>
<input type="text" id="login-username" name="username"
required><br>
<label for="login-password">Password:</label>
<input type="password" id="login-password" name="password"
required><br>
<button type="submit">Login</button>
</form>
`);
});
app.listen(3000, () => {
console.log('Server running on http://localhost:3000');
});
The first step is to turn on status checks for our Git provider in Codacy. Once enabled, Codacy adds a report to our pull requests showing whether the code changes are up to standards or not, as configured on the quality settings of your repository.
We also made status checks mandatory in GitHub by enforcing branch protection on the main branch. If a pull request falls below our organization’s quality standards, it can’t be merged into the main branch until all issues (from the status checks) are resolved.
Let’s go back to Codacy. If we connect the repo and submit the pull request from a new branch, we can see the issues that arise in the security and risk management dashboard:
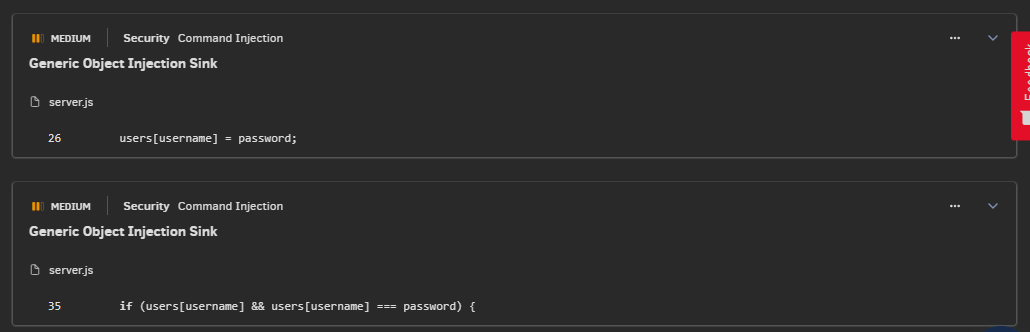
The same report appeared on the repository inside GitHub and also in the Codacy IDE extension for VSCode and JetBrains (so you don’t even have to leave your development environment):
Behind the scenes, Codacy uses various static code analysis tools to identify security vulnerabilities across different languages and platforms. This includes well-known tools such as Semgrep, Bandit, and ESLint. By consolidating results from these diverse tools into one platform, Codacy offers extensive coverage and minimizes the chances of false negatives.
Codacy has highlighted two new issues in the pull request, both of which are of medium severity. We can dive deeper into each problem by clicking on the details:
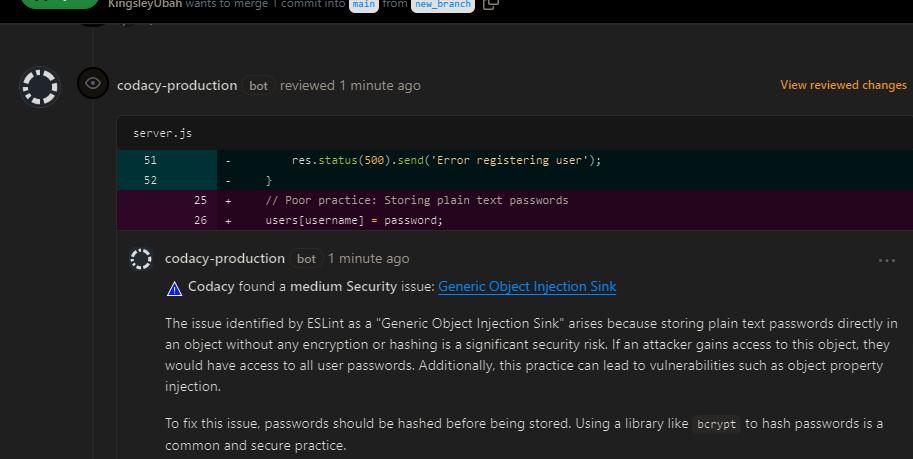
Here ESLint detected that we stored the user’s password in plain text without encrypting or hashing it first, which is a significant security risk. We can easily resolve this issue by hashing all passwords with a library like bcrypt before storing them in the database (we did this in the main branch).
This is a small example, but Codacy runs on every PR. Your team can catch these insecure inconsistencies with every code change before they hit production. Codacy helps enforce secure coding practices by automatically detecting vulnerabilities and providing actionable guidance on fixing them.
If your team practices a non-blocking approach to code reviews, non-reviewed code will often make it to production. As a result, there is a need to enforce a stricter set of standards to keep bugs away from the production branch. Here are some of the steps you can take:
- Extend coding qualities: You can configure more tools and code patterns to catch inconsistencies from a wider range of technologies. Codacy will use the updated configuration when analyzing new commits and pull requests.
- Secrets detection: Codacy scans your repositories (and pull requests) to ensure that sensitive data like passwords, API keys, and cryptographic secrets are not exposed. Trivy, Checkov, and Semgrep all perform multi-language secret detection (Checkov just for IaC stuff).
- Software composition analysis (SCA): Codacy’s SCA tools examine your application’s components for potential security vulnerabilities, licensing issues, or outdated versions. It analyzes the entire software supply chain, including proprietary code and third-party components. Trivy adds SCA capabilities to your IDE via IDE plugins, helping you resolve supply chain issues in real time. We provide proactive SCA to scan pre-existing code for newly registered vulnerabilities (for business-tier customers only).
- Static application security testing (SAST): SAST scans analyze your source code to find patterns that match known coding inconsistencies and security flaws, including OSWAP’s Top 10 list. It offers a crucial layer of proactive security, enabling teams to discover security flaws before they become exploitable problems in production. Codacy provides several tools for performing automatic static security analysis.
- Infrastructure-as-code (IaC): Misconfigurations can happen when IaC scripts contain improper settings, such as exposed ports that should be restricted, unencrypted data transmission, or overly broad security group rules. Codacy uses Checkov to prevent cloud misconfigurations and find vulnerabilities during build-time in infrastructure-as-code, container images, and open-source packages. It also scans GitHub Actions files, among other things.
Furthermore, Codacy users enable stricter quality gate settings (and even broaden test coverage) to reduce bugs and maintain consistent coding standards across the organization. These are the minimum standards for keeping software with time.
Codacy’s Security and Risk Management overview page provides insights into your organization’s security health. The centralized dashboard highlights security risks and compliance issues, allowing teams to identify areas that need improvement and take the necessary steps to boost security status.
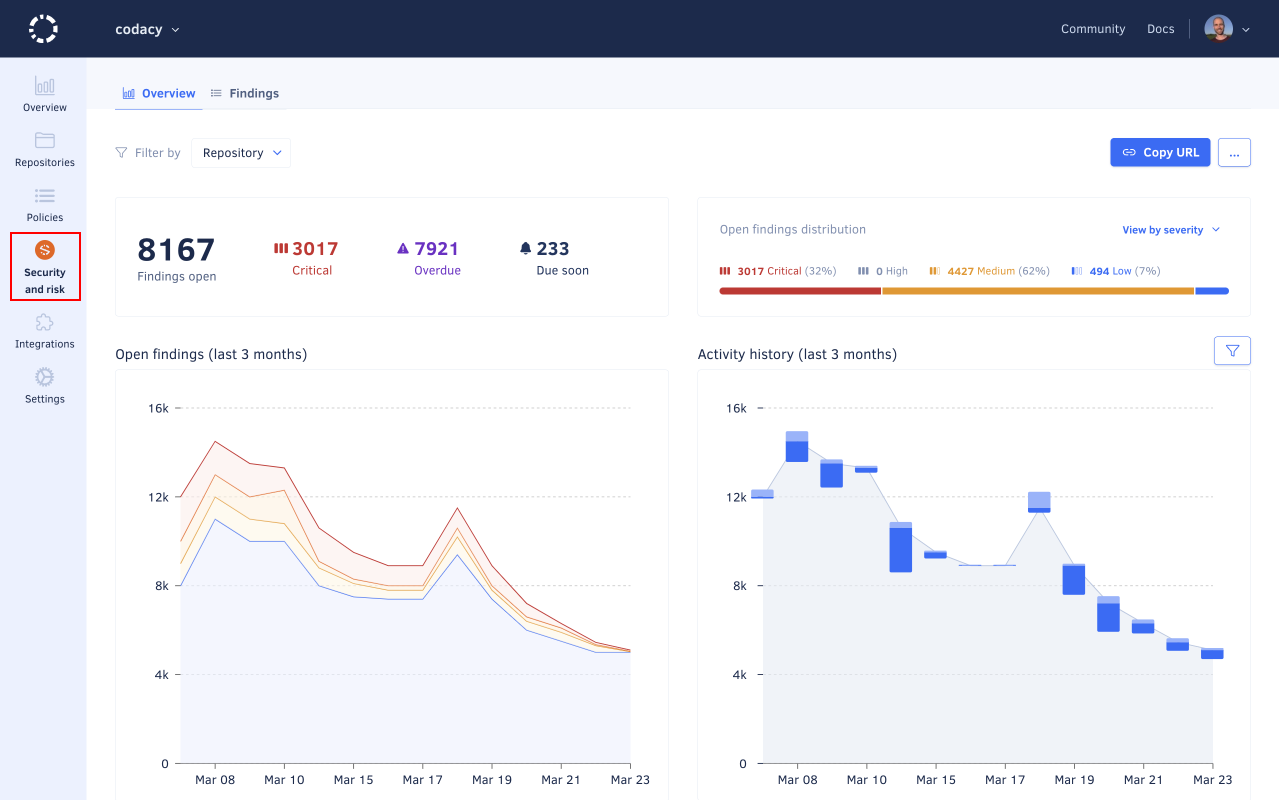
The dashboard displays metrics like the total number of open findings, the distribution of findings by severity, the history of finding resolution, and a breakdown of the most high-risk repositories and most detected security categories. Product leaders can use this information to quickly evaluate their organization's security stance and monitor progress over time.
Codacy provides everything teams need to implement non-blocking code reviews in your organization. It has a built-in automated security scan that detects issues in your repositories and proffers actionable fix advice. You can also configure Codacy to block pull requests that fall below coding standards from merging to the main line.
To give Codacy a try, sign up for a free trial today